This lecture If God Doesn’t Play Dice, Should Doctors was given at the invitation of Leeza Osipenko and Consilium Scientific on May 18th 2023. Consilium are playing a big part in encouraging us all to think more about the quality of proofs we turn to in medicine in particular about Randomized Controlled Trials. There are many excellent lectures on their site.
With lectures like this Bill James and I often ensure there is a back and we did so on this occasion also – so there are versions of this talk If God Does not Play Dice.
This lecture builds on a wonderful phrase from Sander Greenland – First of all do no harm to knowledge. Adapted to our purpose for this lecture it might read Do not sabotage common sense with statistics.
Abel Novoa from No Free Lunch has translated the talk in to Spanish and added some slides – Dios no juega a los dados ¿Deberían hacerlo los médicos?
Ariane Denoyel translated it into French and I gave the French version as a plenary lecture at the Société Française de Pharmacologie et de Thérapeutique. Annual Meeting, in Limoges on June 12, 2023.
It is often said that a lot is lost in translation. But sometimes a translation can uncover new angles on an issue so that it often seems that rather than a translating there has been a re-authoring. Thanks to Abel and Ariane for their re-authorings
Slide 1: If God does not Play Dice: Should Doctors?
Einstein famously said that God does not play dice. Gambling with Dice in France gave rise to probability theory, which led to what we now call medical statistics. 75 years ago we recruited medical statistics in the form of Randomized Controlled Trials (RCTs) to manage our gambles on drugs. RCTs led to Evidence Based Medicine (EBM), which doctors have confidence in when they roll the Drug-Dice – how confident should they be?

Slide 2: Fifty years after the first RCT, in 1998, Don Schell, a tough oilman from Wyoming, was put on Paroxetine for a minor sleep problem. Forty-eight hours later he shot his wife, his daughter and grand-daughter and then himself. His surviving son-in-law took a lawsuit against GlaxoSmithKline (GSK) – Tobin v SmithKline.
In the Tobin case, Ian Hudson, Chief Safety Officer of GSK was asked – Can SSRIs cause suicide. He says GSK practice EBM which means they base their views on randomized controlled trials (RCTs) – which use probability to find the truth.
A jury of 12 plain people, with no background in healthcare dismissed Hudson’s EBM in favor of Evident Based Medicine. Their diagnosis or verdict was it was obvious paroxetine caused this and GSK were guilty of negligence.
Hudson’s view, however, remains ensconced at the top of Britain’s drugs regulator, of which he was later the Chief Executive Officer – as well as top of FDA, EMA, and other regulators.

Slide 3: Hudson’s views originate 70 years earlier in the work of a strange man – Ronnie Fisher. Here you see Fisher smoking a pipe. He dismissed the later link between smoking and lung cancer. Evidence was not Fisher’s strong point.
Fisher was not a doctor and never ran an RCT. Controlled trials and randomization were there before him but his book the Design of Experiments turbocharged them.
Fisher was trying to characterize expert knowledge. Experts know the right answer – like parachutes work for instance. If we set up two groups, one with parachutes and the other not, we would expect those wearing parachutes to live and those not to die.
Someone with webbed feet might behave differently when falling, so we randomize to control for any trivial unknown unknowns like this. Somehow Fisher’s book transformed randomization into something semi-mystical – that would help us overcome ignorance.
Chance was then the only other thing that could get in the way of the expert being right – perhaps a chance strong wind lands a person in snow covered trees. Chance could be assigned a statistically significant value. If 1 in 20 of those without parachutes lived, we wouldn’t say the expert didn’t know what he was talking about.
Fisher‘s expert was not exploring the unknown. Randomization can’t control for ignorance.

Slide 4: Fisher’s expert is a Robin Hood who 19 times out of 20 can split a prior arrow lodged in the Bull. Expertise is precise and accurate.

Slide 5: The RCTs done to license drugs, especially antidepressants, look like this rather than like Robin Hood. A mismatch on this scale indicates we are not dealing with expertise.

Slide 6: Tony Hill ran the first medical RCT in 1947 giving streptomycin for tuberculosis. Hill later put smoking as a cause of lung cancer on the map. He had no time for Fisher. He also knew doctors were not experts. His trial was not a demonstration of expertise. He used randomization as a method of fair allocation – not to manage mystical confounders.
Hill’s RCT found out less about streptomycin than a prior non-randomized trial in the Mayo Clinic, which showed it can cause deafness and tolerance develops rapidly.

Slide 7: In a 1965 lecture, Hill took stock of RCTs. He mentions that it is interesting that the people who are most heavily promoting RCTs are pharmaceutical companies.
He didn’t think trials had to be randomized. He thought double-blinds could get in the way of doctors evaluating a drug. He believed in Evident Based rather than Evidence Based Medicine.
Hill said we needed RCTs in 1950 to work out if anything worked. By 1960, we had lots of drugs that worked, none discovered by RCTs and the need was to find out which drug worked best. This is not something RCTs can do – there is no such thing as a best drug.
He also said that RCTs produce average effects, which are not much good for telling a doctor what to do for the patient in front of them.
Hill is saying here that RCTs can help evaluate one thing a drug does which means they are not a good way to evaluate a drug overall. All RCTs generate ignorance but we can bring good out of this harm if we remember that. Hill never saw RCTs replacing clinical judgement.

Slide 8: This 1960 RCT run by Louis Lasagna makes Hill’s point. Thalidomide has therapeutic efficacy as a sleeping pill but this trial missed the SSRI-like sexual dysfunction, suicidality, agitation, nausea and peripheral neuropathy it causes.
Two years later, Lasagna was responsible for incorporating RCTs into the 1962 FDA Act – in order to minimize the chance of another thalidomide. By doing this, he was, more than anyone else, the man who got us using RCTs. The mechanism he put in place to stop thalidomide happening again was one it sailed through.
Slide 9: Many claim RCTs demonstrate cause and effect in a way no other design can.
The 1950s gave us better antihypertensives, hypoglycemics, antibiotics and psychotropic drugs than we have ever had – all without RCT input.
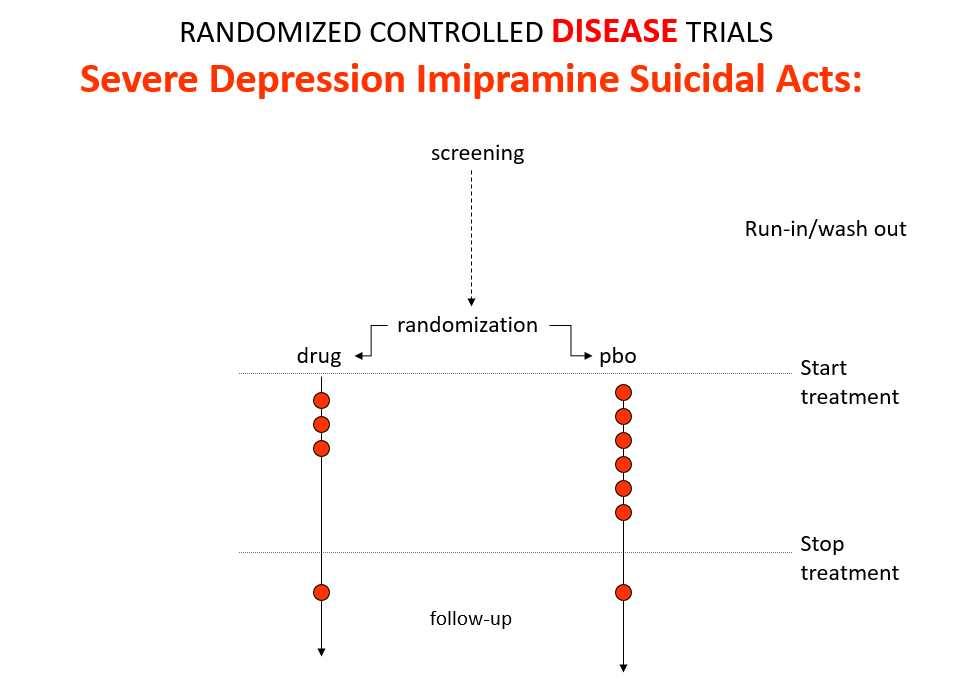
Imipramine, the first antidepressant, is much stronger than SSRIs. It can treat melancholia –SSRIs can’t. Melancholia comes with an 80-fold increased risk of suicide.
Imipramine was launched in 1958. At a meeting in 1959, experts noted that while it was a wonderful treatment it made some people suicidal. Stop the drug and the suicidality clears. Re-introduce it and suicidality comes back. This was Evident Based Medicine.
In an RCT of imipramine versus placebo in melancholia, we would expect the red dots showing suicide attempts to be less on imipramine even though it can cause suicide because it treats this high risk condition. This RCT would look like evidence imipramine cannot cause suicide.
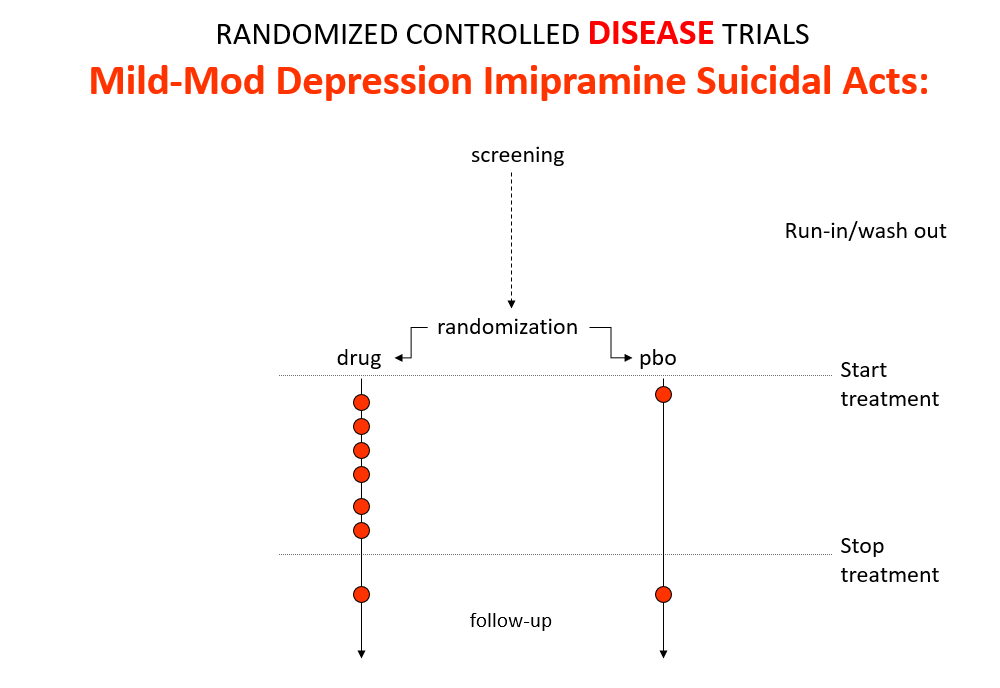
Slide 10: In the mild depression trials that brought the SSRIs to market – there is an increase of suicidal events compared to placebo in people at little or no risk of suicide.
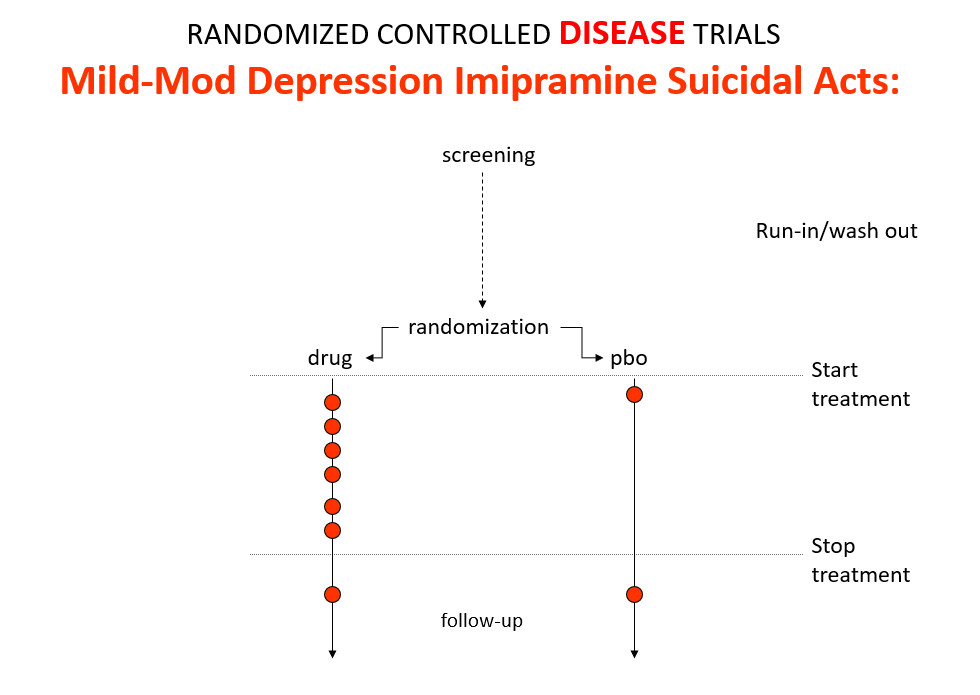
Slide 11: Used as a comparator in these trials imipramine now too causes suicides.
The diametrically opposite answers stem from the fact these are Treatment Trials not Drug Trials. If the condition and treatment produce superficially similar effects, RCTs cause confounding not solve it. This is true for most medical conditions and their treatments.
When a patient becomes suicidal in a trial you have to use your judgement to work out what is happening but in RCTs clinicians are not supposed to use their judgment.
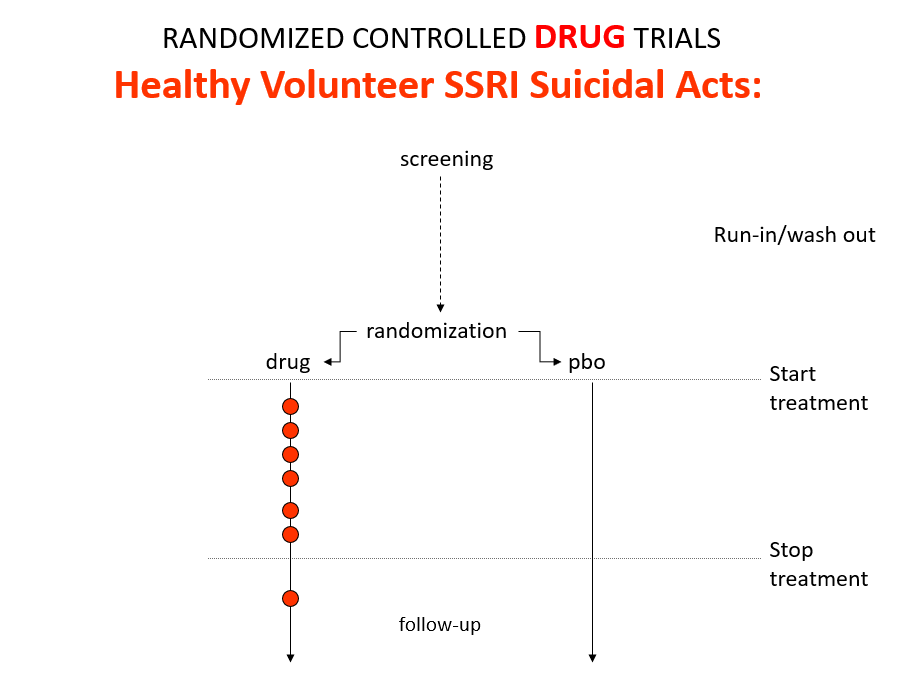
Slide 12: Here is what a Drug Trial looks like. In healthy volunteer studies in the 1980s, companies found SSRIs cause volunteers to become suicidal, dependent and sexually dysfunctional. We heard nothing about these problems when the drugs launched in part because Drug Trials enabled companies to engineer Treatment Trials to hide these problems.

Slide 13: There are more dead bodies on SSRIs than on placebo in trials, yet the RCTs as Ian Hudson told you show the drugs work. This is because working is measured on a surrogate outcome. For antidepressants it’s the Hamilton Rating Scale for Depression. Fifteen years after its creation, Max Hamilton commented on his scale:
It may be that we are witnessing a change as revolutionary as was the introduction of standardization and mass production in manufacture. Both have their positive and negative sides
Hamilton saw this scale as a checklist of things to ask about in an interview – a mixed blessing.

Slide 14: What does he mean? Well the Hamilton scale has suicide, sex, sleep, appetite and anxiety items, all of which can be affected by the condition or the treatment. If Leeza is on an SSRI trial and I ask her if she has been suicidal in the last week and she says Yes, I should score a 4 – but in fact if the drug has caused it I should score 0. But researchers are not allowed to use a judgement call – the default is to the illness. The process is algorithmic – there cannot be a trace of human judgement in there.

Slide 15:
This image is from the James Webb telescope. Confidence Intervals were introduced by Gauss in 1810 to solve a telescope problem. Because of measurement error, telescopes then often failed to establish if there was one or two stars in a location. As measurement errors should distribute normally, confidence intervals could help distinguish individual stars.

Slide 16: In addition to randomization, Fisher put Statistical Significance on the map. By 1980 every leading medical statistician was saying we need to get rid of statistical significance in favor of Confidence Intervals. Confidence intervals are more appropriate for measurement error but is this what we have in Treatment Trials?
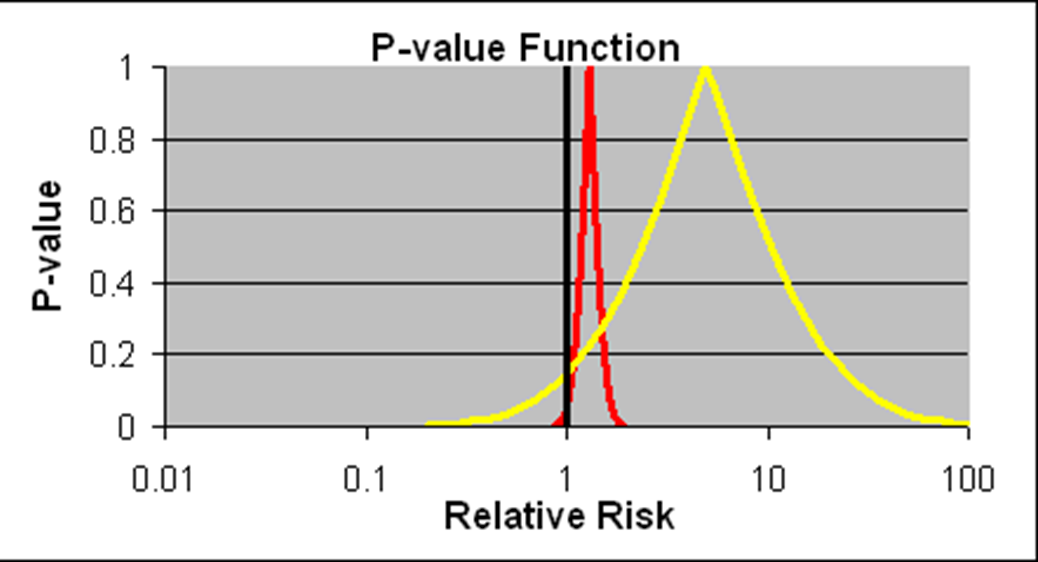
Slide 17: Confidence intervals allow us to estimate the size of an effect and the precision with which it is known. The details on the likelihood of the Red Drug killing you here are more precise than for the Yellow Drug. The best estimate of the lethality of the Yellow Drug however is greater. The standard view is that if we increase the size of the Yellow Drug Trial, we will have greater precision and know better what the risks are. This is wrong.
If you are forced to take one of these drugs, as things stand now, Ian Hudson, FDA and WHO say the only dangerous drug here is the Red One. This is because more than 95% of the data, more than 19 out of 20 lie to the right of the line through 1.0. This is exactly what experts like Sander Greenland now say is wrong.
I would take the Red Drug because as you will see these confidence intervals are not managing measurement error. We don’t know what they mean. For 100 years authoritative voices said we should not assume we know the link between data like these and real life.
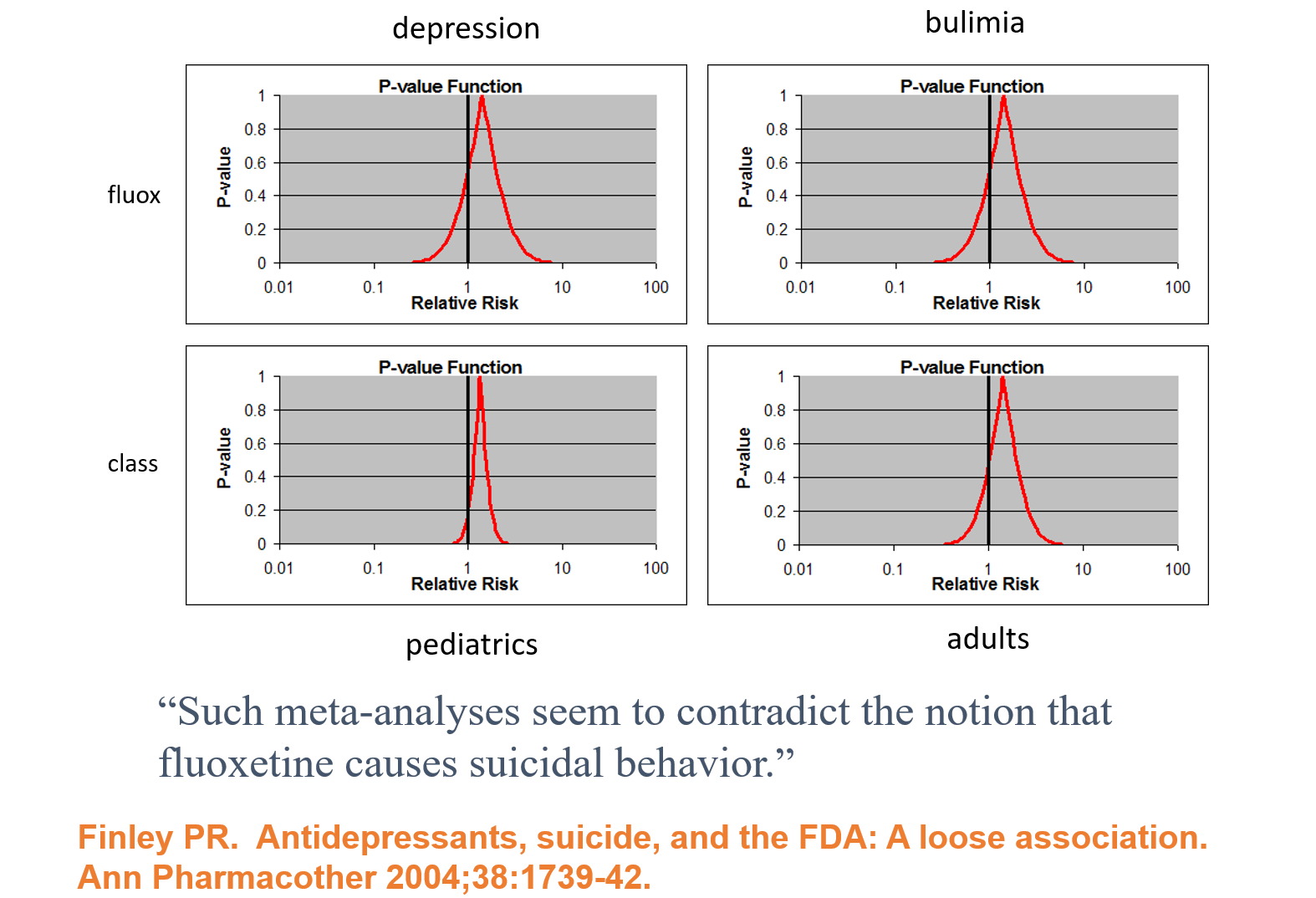
Slide 18: In 1991, facing claims Prozac caused suicide, Lilly analysed their RCTs and spun the Confidence Intervals here as evidence Prozac does not cause suicide. This is Ian Hudson thinking – there is no problem as nothing is statistically significant.
Leading experts like Sander Greenland say this is wrong – and it would be better to read these p-values as compatibility intervals – all in this case pointing to the data being largely compatibility with Prozac causing suicidal events.
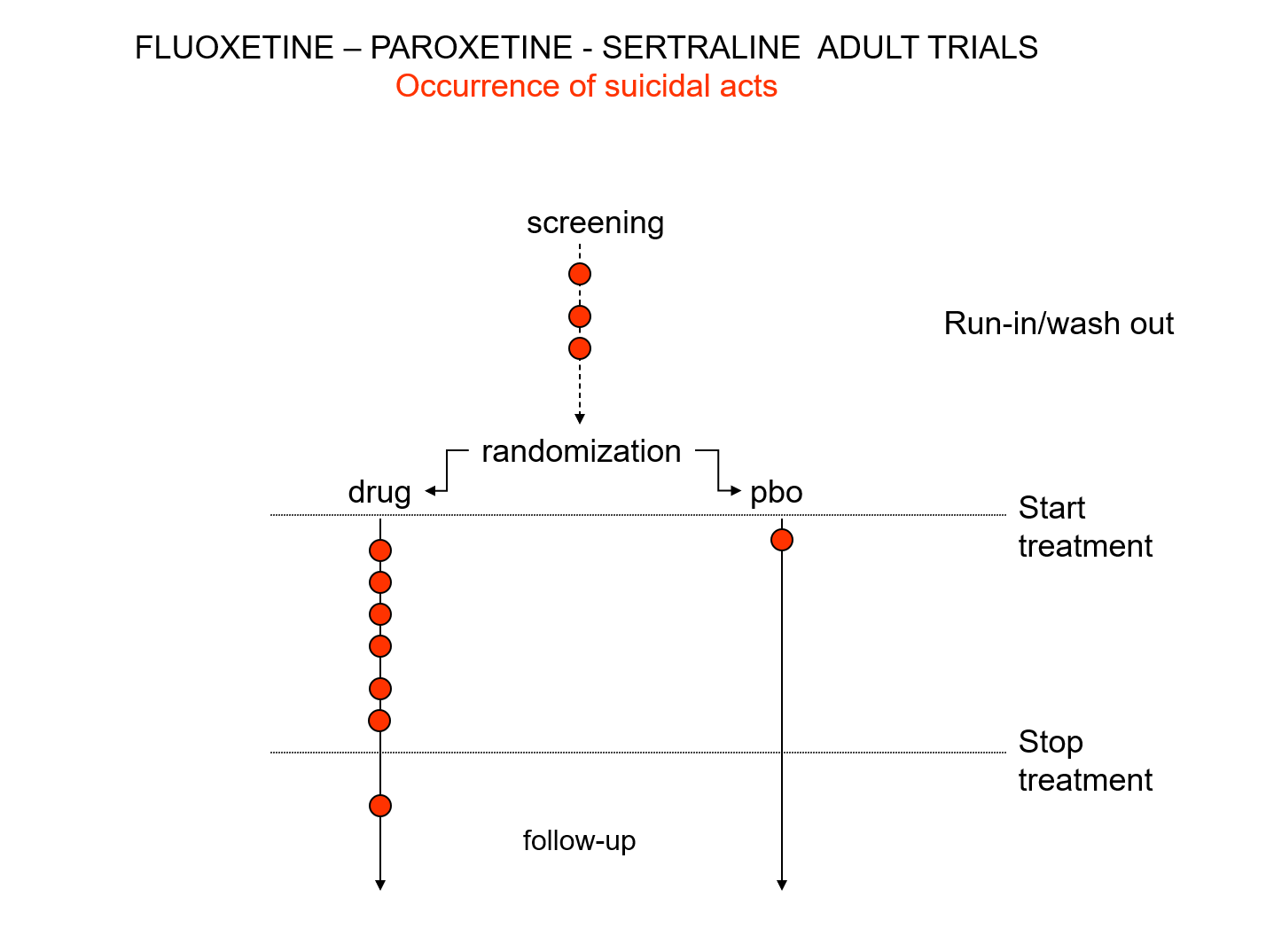
Slide 19: Here is a representation of suicidal events from the trials bringing Prozac, Seroxat and Zoloft to market around 1990. Note the events under screening. Screening means a 2 week washout period before a trial starts where people are taken off prior drugs before being put on the new treatment or placebo. This phase of a trial is dangerous – people are in withdrawal and may become suicidal.
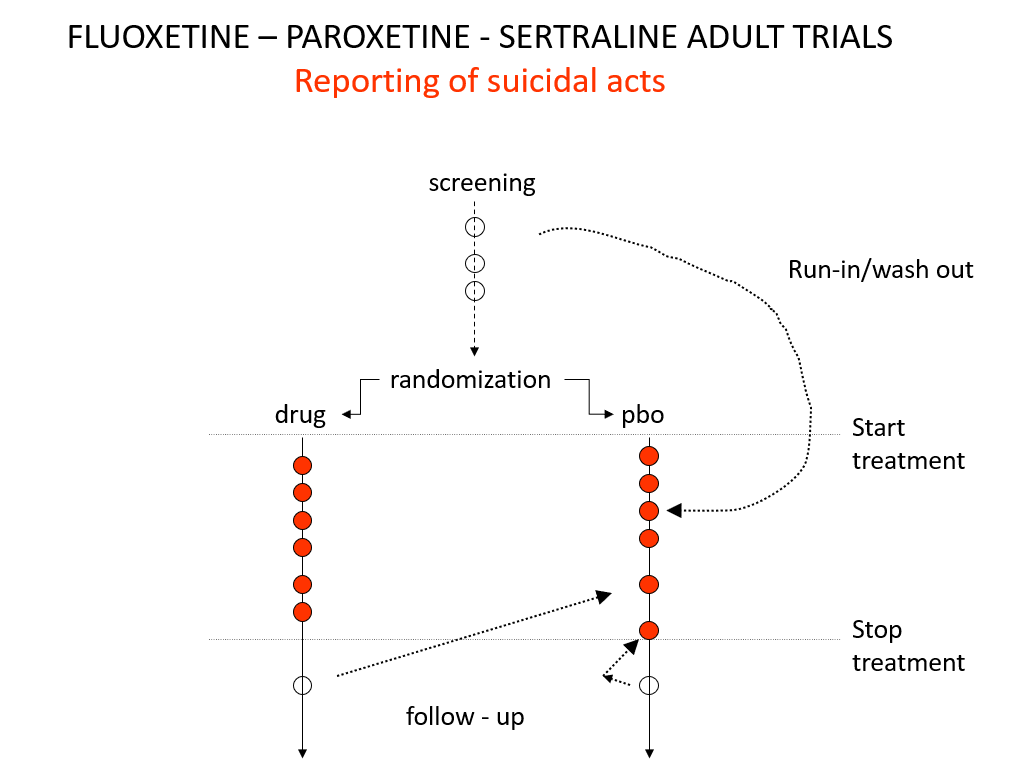
Slide 20: When submitting the data to FDA, the companies moved events as you see here. Their argument was that people in the run in phase were not on active treatment – which is equivalent to being on placebo. There were other maneuvers at the end of the trials as ou see here.
Even with these maneuvers, there was an excess of suicidal events on SSRIs but the 95% confidence interval was no longer to the right of 1.0. Why do this? Because regulators and companies need a Stop-Go mechanism and statistical significance provides this. But doctors don’t need an external Stop-Go mechanism to replace their clinical judgement, so why do we go along with this?

Slide 21: Nobody noticed these maneuvers in 1990, but 14 years later in a crisis about children becoming suicidal on SSRIs, questions were asked. GSK and Pfizer responded:
‘GSK did not intentionally submit any erroneous or misleading information to FDA. The suicide data submitted to FDA explicitly identified when events occurred during the placebo run-in period. FDA had all this information right from the beginning.’
“Pfizer’s 1990 report to FDA plainly shows … that 3 placebo attempts as having occurred during single blind placebo phases… FDA has neither criticized these data or the report as inappropriate, nor required additional analyses”.
These maneuvers breach FDA regulations. FDA staff noted this breach, but senior FDA figures ignored this and even put their name to articles that embraced these breaches of regulation – using the illegitimate figures to argue placebo controlled RCTs were not unethical, as those on placebo were not at any greater risk than those on treatment.
FDA and companies liaised closely over the suicide crisis in 1990. Criminally? Perhaps. I prefer the idea that FDA were adopting a position of strategic ignorance.
There is a crisis in knowledge production here. This is not something you can expect FDA to take a lead on – they are bureaucrats. Companies create knowledge or the appearances of knowledge at this point. Doctors, however, are surely primarily responsible for the creation of medical knowledge. Doctors, though, were missing in action around 1991.
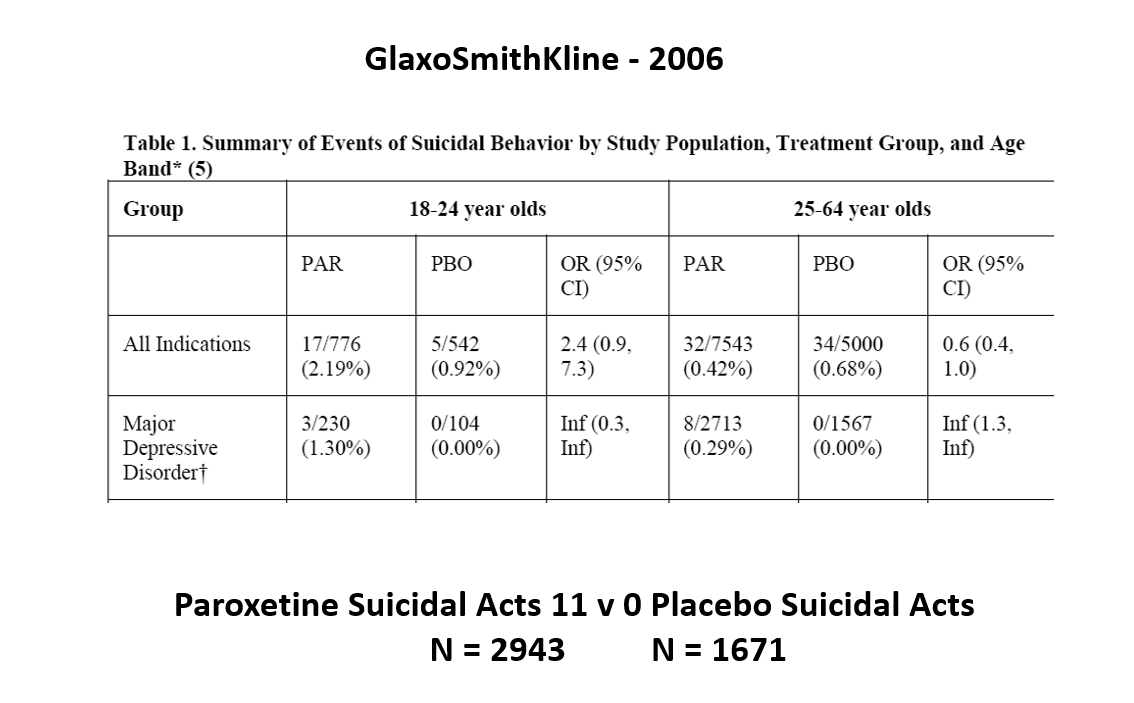
Slide 22: The sacred mantra of RCTs is randomization controls for all possible confounders in all possible universes. Randomization introduces confounders into clinical trials.
The images for the next 3 slides come from a GSK paper prepared in 2006 for submission to FDA. The small print is hard to read – the bold at the bottom gives you the key details.
The suicidal event data for Paroxetine in Major Depressive Disorder trials in this slide show it causes suicidal events. But randomization is about to come to GSK’s rescue.

Slide 23: Here you see GSK did 2 trials in Intermittent Brief Depressive Disorders (IBDD) patients who have regular suicide attempts. Paroxetine didn’t do well – one trial was stopped it was doing so poorly. Why do these trials?
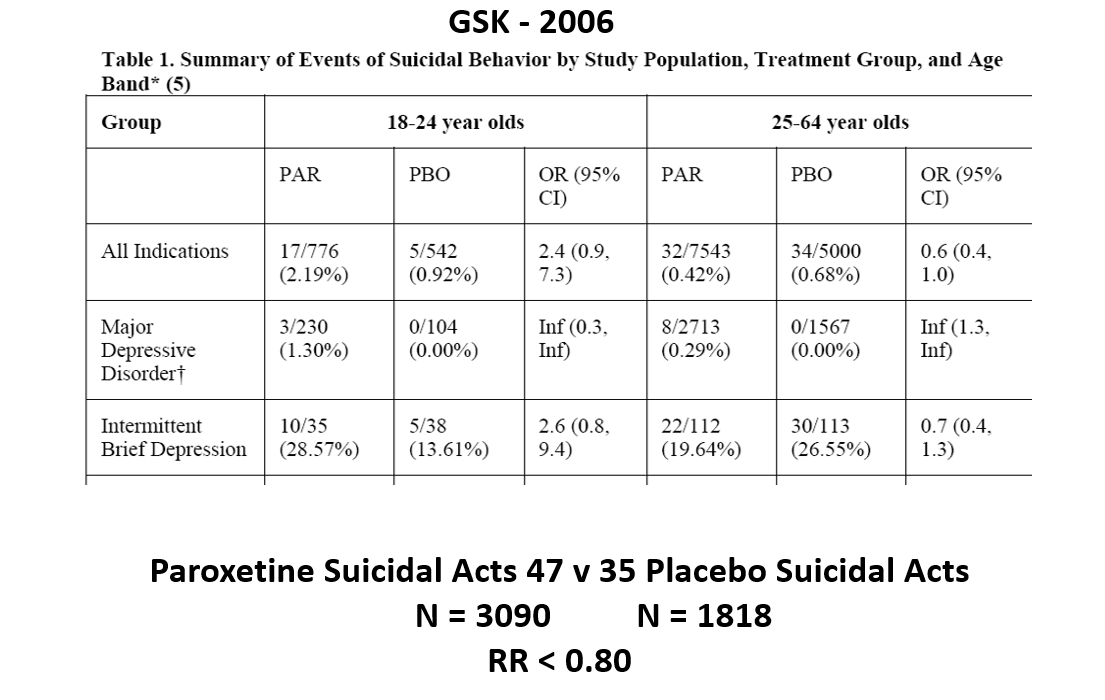
Slide 24: When you add these figures together suddenly paroxetine protects against suicide. First you need to know IBDD patients could be admitted to MDD trials – we have no way to distinguish them. Some patients become IBDD by virtue of a poor response to an SSRI. What will happens if IBDD patients are in an MDD trial is the same as if you add the groups of trials together as we did here – just this scenario makes the issues more clear.
This scenario can happen every time a medical condition is heterogenous – as diabetes, dementia, parkinson’s disease, breast cancer, back pain, hypertension and most medical conditions are. In these cases, randomization will hide effects good and bad – and enable us to use a problem a drug causes to hide a problem a drug causes.

Slide 25: Graphically the Red Drug here is the MDD curve alone – more than 95% of the data are to the right of the 1.0 line. The traditional wisdom is that adding some more events to the Red Drug trials should give us a more precise version of the same estimate.
Adding roughly 3% more in this case, we have shifted the curve to the opposite side of the 1.0 line. It’s a more precise confidence interval but this precision speaks to our ignorance rather than to better knowledge. No medical statistics book ever hints at this possibility.
We could add 40 suicidal events to the paroxetine IBDD arm before GSK would have to admit Paroxetine causes a problem – on the basis that the results are now statistically significant.
Confidence intervals do not help us work out what is going on in these cases. Nor do they help in heterogenous drug responses. If we clone a David who is sedated by a Red Drug and an Ian Hudson who is stimulated by it, the best estimate of the Red Drug’s effect will lie on the 1.0 line, apparently showing this drug has no effect on sleep. A method to distinguish between one and two stars should not produce an answer that there are no stars. Algorithmic judgements cannot substitute for a human judgement.

Slide 26: Let us return to the James Webb Telescope to make a point. Confidence intervals were a step on the way to revealing the individuality of stars. In medicine now, statistical approaches operate against individuality.
We think that using Chance to control Bias is scientific and so we allow mindless algorithms to replace clinical judgement. Clinical medicine, like law, and the first 300 years of science, used Bias to Control Chance. Clinical medicine needs to re-assert the validity of this approach.

Slide 27: The view that RCTs offered the most scientific way to establish if a drug has adverse effects was emerging in 1983, as this quote by Rossi et al indicates:
Spontaneous reporting is “the least sophisticated and scientifically rigorous . . . method of detecting new adverse drug reactions.
Louis Lasagna, the man who in 1962 more than anyone introduced RCTs, responded:
This may be true in the dictionary sense of sophisticated meaning ‘adulterated’ . . . but I submit spontaneous reporting is more ‘worldly-wise, knowing, subtle and intellectually appealing’ than grandiose, expensive RCTs.

Slide 28: In 1990 in this Teicher et al article, 3 clinicians claimed fluoxetine made 6 people suicidal. Following traditional clinical approaches for determining causality, this article nailed beyond doubt that fluoxetine could cause some people to become suicidal.
Lots of other groups reported similar findings. I published 2 cases of men, who were challenged, dechallenged and rechallenged with an SSRI. The only way to explain what happened was that fluoxetine caused it. This was Evident Based Medicine.

Slide 29: Almost the same week as my article came out, BMJ published an article in which Lilly claimed an analysis of their RCTs showed no evidence Prozac made people suicidal. The cases reported, therefore, they said were sad but anecdotal – and the plural of anecdote is not data. Depression was the problem not fluoxetine. Clinical trials are the science of cause and effect. The challenge to doctors and others was whether we were going to believe the science or the anecdotes?
This was a knowledge creation moment that likely had input from all companies and perhaps FDA. This article created Evidence Based Medicine and just as with RCTs 30 years earlier, the people most commonly exhorting doctors to practice EBM today are Pharma companies.
In fact, the original phrase is the plural of anecdotes is data – otherwise Google wouldn’t work.
The idea the disease is responsible for suicide attempts and suicides in healthy volunteers is hard to believe but companies can wheel out experts to say just that.
The Teicher paper is the science – the Lilly data is an artefact. My challenge to you is which are you going to believe the Science or the Artefact? The made by algorithm approach, combined with inappropriate statistics, creates artefacts not science.
Lilly cooked the data. When you get the trial data, the Evident Based Medicine and Evidence Based Medicine approaches here can be reconciled – as you might expect with real science. An incompatibility would not be a problem for real science, which progresses by resolving discrepancies.
Lilly, however, were not in the business of embracing discrepancies. Their argument was a religious one – a dogmatic one. They forbid us to believe the evidence of our own senses.
Peter Drucker, the doyen of marketing said the goal of marketing is not to sell more Prozac but to own the market. This was the moment Pharma took ownership of the market.
This ownership allows companies to dictate what the risks, the benefits and the trade-offs of drugs are. Allows them to force us to live the lives they want us to live rather than engage with the risky and unprofitable business of producing products that will help us to live the lives we want to live.
Medicine has traditionally been about bringing good out of the use of a poison. Lilly and other companies are bringing poison out of the good of people volunteering for clinical trials with one of the most serious breaches of scientific method in the 360 plus years we have had science.

Slide 30: What is science? The usual histories start with the foundation of The Royal Society in 1660. It established the ground rules – Science would deal with matters that could be Settled by Data. Participants could be Xtian, Hindu, Jew, Muslim, or Atheist, but they were called on to leave these badges at the door and come to a consensus about the best way to explain the experimental outcome in front of them.
The histories of science emphasize the word Data. Settled is a more important word. Statistics played no part in this science. The experiments were events that didn’t need statistical descriptions. Science does not replace judgment calls with a statistical artefact – this only began 33 years ago.

Slide 31: This history overlooks an event in 1618, when Walter Raleigh was executed – for being too close to the French and Spanish. Raleigh was convicted on the basis of things said about him by people who did not come into court to be cross-examined.
The legal system recognized an injustice and introduced Rules of Evidence. Hearsay could not be used as evidence. Jurors – a group of 12 people, Xtians, Hindus, Muslims, Atheists and Jews, can only base a verdict on material put in front of them that can be examined and cross-examined. The process of forcing 12 people with very different biases to come to a Verdict about what is in front of them is the essence of science.
Verdicts and diagnoses are provisional, which might appear to contrast with the objectivity of science, but scientific views are similarly provisional. Scientists attempt to overturn verdicts with new data.
Let’s say I gave Leeza fluoxetine 33 years ago and she became suicidal. I could examine and cross-examine her, run labs and scans, raise the dose, stop the drug, add an antidote, have a case conference with all of you able to ask questions to see if we could explain this in any other way. She is the data, the apparatus in which the experiment is taking place.
If Leeza and I and you conclude fluoxetine made her suicidal and report this to MHRA or FDA, the first thing FDA will do is to remove her name. No-one can now examine or cross-examine her and come to a scientific view about whether there is a link or not. Her injury has been made Hearsay – misinformation.
If you are later injured in the same way and see tens of thousands of reports of suicidality on SSRIs on FDA’s adverse event reporting system, you cannot bring this into court because no-one can be brought into court. It’s Hearsay not Evidence.
Company RCTs are equally hearsay and should not be let into Court as evidence. Accessing the data means accessing people – like Leeza or me – and we cannot do that with subjects in company trials, who often don’t exist. Company articles are ghostwritten and the authors, who have seen none of the patients, cannot speak to what happened either.
In contrast, if Leeza and I report her case in a Medical Journal as a Case Report, with our names on it, this is evidence and we can both be brought into Court.

Slide 32: In 1997, you have Lasagna here saying:
In contrast to my role in the 1950s which was trying to convince people to do controlled trials, now I find myself telling people that it’s not the only way to truth.
Evidence Based Medicine has become synonymous with RCTs even though such trials invariably fail to tell the physician what he or she wants to know which is, which drug is best for Mr Jones or Ms Smith – not what happens to a non-existent average person.
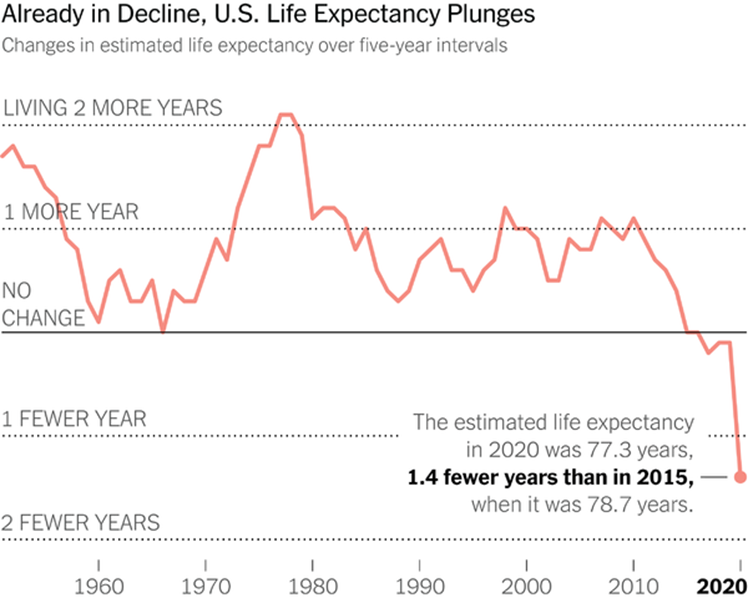
Slide 33: Since roughly 1980, RCTs have been creating a scenario where drugs have benefits and not problems. This is leading to polypharmacy.
As of 2016, over 40% of over 45s in the US were on 3 or more drugs every day of the year. Over 40% of over 65s on 5 or more drugs every day of the week. And in parallel with this Life Expectancy, especially in the United States is falling.
Reducing medication burdens can increase life expectancy, reduce hospitalizations, and improve quality of life.

Slide 34: Deprescribing is the primary medical task of our age. But reducing a medication burden is not easy – as this image from The Hurt Locker movie illustrates. Many of these drugs explode on attempting to withdraw them. If this doctor believes the medical literature he’s dead
No RCT will ever help with this. The best evidence will lie in clinical experience of tackling similar situations. Being able to talk to clinical colleagues will help but the key scientific partner is the patient – who brings clues from missing doses of some of these drugs, and a sense of what the drugs are doing that can only be accessed through them. The patient is the apparatus in which the experiment is taking place and each patient and their response to drugs is unique.

Slide 35: We began with Einstein. Ein Stein means one stone – one shape. Up till now, we have had no mathematics that might counter the averaging we get from medical statistics.
Mathematics is more about shapes than numbers and earlier this year a New Shape was discovered, the first single aperiodic shape – that means it cannot be incorporated into other shapes or averages. This offers us a new robustly individual mathematics – a better template for clinical practice than rolling dice has been.
Statistically anointing the figures…
‘But researchers are not allowed to use a judgement call – the default is to the illness. The process is algorithmic – there cannot be a trace of human judgement in there.’
‘A jury of 12 plain people, with no background in healthcare dismissed Hudson’s EBM in favor of Evident Based Medicine. Their diagnosis or verdict was it was obvious paroxetine caused this and GSK were guilty of negligence.’
Perhaps GSK, are following the Model of Boeing – aeroplanes are the safest mode of travel, but then safety can unravel if you lose your bolts…
Playing Dice
What are the chances of aeroplanes crashing, and loose bolts coming off the fuselage
‘The miracle that disrupts order’: mathematicians invent new ‘einstein’ shape
Called ‘the hat’, the 13-sided shape can be arranged in a tile formation such that it never forms a repeating grid
An 18-month inquiry into the two Boeing 737 MAX crashes that left 346 people dead concludes, identifying a “horrific culmination” of failures at the company and among regulators.
The damning report reads: “The crashes were not the result of a singular failure, technical mistake, or mismanaged event.
“They were the horrific culmination of a series of faulty technical assumptions by Boeing’s engineers, a lack of transparency on the part of Boeing’s management, and grossly insufficient oversight by the FAA.”
The central point focused on the flight control software, known as MCAS.
The inquiry team highlighted “faulty design and performance assumptions” in the system.
Airline finds loose bolts on Boeing aircrafts days after plane door blown off mid-flight
No one was seriously injured, but the incident has spooked airlines and authorities, who ordered dozens of 737-Boeing Max aircraft in the US to stay grounded.
Days later, United Airlines says it has found loose bolts on plug doors on multiple Boeing 737 MAX 9 aircraft during inspections.
A statement from Boeing said: “As operators conduct the required inspections, we are staying in close contact with them and will help address any and all findings.
“We are committed to ensuring every Boeing airplane meets design specifications and the highest safety and quality standards. We regret the impact this has had on our customers and their passengers.”
Spirit AeroSystems, a subcontractor which installed the door plug that blew out of the Alaska Airlines plane, said in a statement that “quality and product integrity” are a priority.
It said: “Spirit is a committed partner with Boeing on the 737 programme, and we continue to work together with them on this matter.”
‘FDA and companies liaised closely over the suicide crisis in 1990. Criminally? Perhaps. I prefer the idea that FDA were adopting a position of strategic ignorance.’
Strategic ignorance – are the nuts tight enough?
How they are related:
Ian Hudson has had a varied career as a pediatrician, a discredited expert in clinical trials, then CEO of the MHRA. In 2019, it was the MHRA’s loss and Africa’s gain when the revolving door morphed him into a senior adviser for the Gates Foundation.
He pairs up with Nevena Miletic of Roche to promote the new, much needed, African Medicines Agency.
https://twitter.com/IFPMA/status/1638883475288735746
He now speaks on topics like “Expanding Regulatory Science: Regulatory Complementarity (sic) & Reliance”
Back in 2012 Hudson had created the International Coalition of Medicines Regulatory Authorities (ICMRA) with himself as chair.
By a strange quirk of fate the current chair of the ICMRA (who must have time on her hands when not reading novels) is none other than Emer Cooke, in a previous life employed by the European Federation of Pharmaceutical industries and Associations (EFPIA), but currently boss of the EMA.
Without the benevolence of Pharma our Regulators would be floundering.
Small world.
Sarah knew all about it in 2001 – and in 2004 “the system is dangerously secretive, riddled with conflicts of interest, and indelibly flawed by chaotic and incompetent procedures for evaluating drug benefits and risks.
Enter Ian Hudson
only randomised controlled trials will do.
“randomised control trials are the wrong tool”
So what does Mr Hudson think?
who, exactly, was steering them as to what it meant.
Swallowing the company line
It’s time we had proper, open trials on the Prozac family of antidepressants
Sarah Boseley
Thu 14 Jun 2001
There’s a big black hole in Harlow in Essex. With apologies to the people of Harlow, whose town is probably irreproachable in every other way, there is a big black hole. It belongs to GlaxoSmithKline, the world’s biggest drug company, and it is allowed to continue to exist by the complacency of the Medicines Control Agency, which is supposed to watch over the safety of people who take medicines.
We’re not talking about hospital medicines here – we’re talking about the antidepressant Seroxat. It’s GSK’s version of Prozac. Like Prozac, it is handed out by GPs – not usually by psychiatrists – to ordinary individuals like you or me who are depressed.
Seroxat, Prozac, Sertraline and the others in the SSRI (selective serotonin reuptake inhibitor) class became blockbuster earners for their manufacturers not least because they were marketed as being super safe. People couldn’t get hooked on them as they did on the older drugs such as Librium and Valium, claimed the companies.
For over a decade, the company line has been swallowed, along with the pills. But a court case in Wyoming, USA, has changed all that. The jury decided Seroxat – Paxil in the USA – was to blame for Donald Schell killing his wife, daughter, baby granddaughter and then himself. And a British psychiatrist unearthed studies in GSK’s archives which show that healthy company employees without any hint of depression, recruited in the earliest trials of Seroxat in the UK, not only got agitated and had abnormal dreams, but they also got hooked.
Enter Ian Hudson, witness for the defence and at the time of his deposition earlier this year, worldwide safety director for GSK. That’s Ian Hudson, now director of licensing at the Medicines Control Agency in the UK.
What did he have to say to the evidence of Mr Schell’s closest remaining family and three psychiatrists who all believed the tablets of Paxil/Seroxat Mr Schell took for just two days precipitated him into an unnatural and totally uncharacteristic murderous and suicidal frenzy? His position is that an individual case cannot tell you one way or the other – only randomised controlled trials will do.
The Harlow black hole looms. Harlow is where GSK keeps its archives – those unpublished studies showing the side-effects experienced by healthy people taking the drug. They are not randomised controlled trials – where half the volunteers are given the drug and the other half get a dummy pill, nobody knows who has which and their responses are carefully observed.
But David Healy, a psychiatrist from North Wales and a leading historian of antidepressants who gained access to the archives through the court case, says that randomised control trials are the wrong tool to establish whether serious side effects are occurring. The way to investigate what is happening is to carry out a challenge-rechallenge trial, where people are given the drug, taken off it and then put back on.
But GSK has not carried out that sort of study to establish whether or not Seroxat can make people agitated, suicidal, murderous or hooked. Nor has it carried out a randomised controlled trial. Here is the black hole. There is no proof that the drug does these things, says GSK, and because of that there is no reason to carry out trials that might decide it one way or the other.
Does Mr Hudson still take that view now he is at the MCA, which watches over the safety of the British public? “If he takes the position with the MCA that he took at the trial, then none of us is safe with any drug in the UK at the moment,” says Dr Healy. How would Mr Hudson even be able to blame alcohol for making someone drunk?
So what does Mr Hudson think? As always, the MCA declined to answer detailed questions.
It will be interesting to know what they conclude – if they deign to tell us. The MCA will have been supplied with all the healthy volunteer data before it granted the licence for Seroxat. It doesn’t seem to have been worried then, which makes one wonder who, exactly, was steering them as to what it meant.
The riddle of the drug regulators
Critics press for review of licensing system
Sarah Boseley, health editor
Sat 13 Mar 2004
The suggestion is that the regulating authorities and the drug companies are too closely interrelated. Key figures not only on the CSM but also in the Medicines and Healthcare Products Regulatory Agency – the drug licensing body which it advises – have a history of consultancy, research or even employment by pharmaceutical companies. Ian Hudson, for instance, the worldwide safety director of GlaxoSmithKline (GSK) until 2001, is now director of licensing at the MHRA.
The MHRA and CSM say that they have to draw on the expertise of a relatively small pool of highly qualified individuals who inevitably have gained their experience in the industry, but critics say it would be possible to find academics who are completely independent.
One of the fiercest critics, Charles Medawar of the consumer group Social Audit, will allege in a book to be published on Tuesday, Medicines Out of Control?, that the system is dangerously secretive, riddled with conflicts of interest, and indelibly flawed by chaotic and incompetent procedures for evaluating drug benefits and risks.
https://www.nursingtimes.net/archive/special-report-the-seroxat-scandal-07-03-2008/
GSK has rejected claims that it withheld information. Dr Alastair Benbow, medical director for GSK Europe, said: ‘We firmly believe we acted properly and responsibly in first carrying out this important clinical trials programme and then informing the regulatory agencies when we identified a potential increased risk of suicidal thinking and behaviour in patients under 18.
‘GSK is committed to working with the government, appropriate regulatory authorities and other pharmaceutical companies to take whatever action is necessary to improve legislation and policy in this area.’
‘the key scientific partner is the patient’ – who is the frequent flyer; not the goons who have dicey ‘quality of proofs’
as thick as thieves…
‘cast doubt on the quality of the development of clinical trials conducted by the pharmaceutical industry.’
recovery&renewal reposted
Harriet Vogt
@shvogt
‘We are not acting against antidepressants, but against a policy of non-information which presents antidepressants as a happiness pill,” says the lawyer for the two families.’
MISSD
@MISSDFoundation
Bereaved parents in France have joined together to file complaints about the serious & sometimes fatal adverse effects of #paroxetine. Both families lost sons to sudden and out-of-character death shortly after their sons started the drug.
https://www.lepoint.fr/sante/antidepresseurs-deux-familles-portent-plainte-apres-le-suicide-de-leurs-fils-19-01-2024-2550189_40.php#11
Investigation unit of Radio France
Friday, January 19, 2024 at 5:00 am
https://www.francebleu.fr/infos/sante-sciences/le-combat-de-familles-pour-alerter-sur-les-dangers-des-antidepresseurs-9294082
Irène Frachon then told them: “The question of the potential dangerousness of psychotropic drugs [chemical substances that act on the psyche, such as antidepressants, editor’s note] is one of the strong warnings that have historically cast doubt on the quality of the development of clinical trials conducted by the pharmaceutical industry. It aims to serve its interests by highlighting the benefits of its products rather than the side effects.”
Words that have been echoing in the heads of Vincent Schmitt and Yoko Motohama ever since. Because they correspond to what happened with the antidepressant taken by Romain and Florian, marketed by GSK. The company has been aware of the risk of suicide that its drug can cause for a long time. A court case in the United States has revealed this. In 2012, GSK paid a record $3 billion fine for withholding data about the dangers of its paroxetine-based antidepressant.
When GSK faked its data
If the justice system has had proof of this, it is thanks to an Irish whistleblower, the psychiatrist David Healy. “My alert was aimed at proving that the GSK laboratory had knowingly deceived people. Members of the attorney general’s office learned that I had a document showing that GlaxoSmithKline knew that the results of its tests were negative,” he said. The psychiatrist found that clinical trials, particularly those conducted on adolescents, were biased. When some of them expressed their desire to commit suicide on antidepressants, they were excluded from the experiment without the reason for this eviction being clearly specified.
When they discover this story, Romain’s parents sift through thousands of declassified American documents. Vincent Schmit still can’t believe it: “In the conclusion of the (GSK) report, basically, it says that the drug is fantastic, that it works for kids and that it saves everyone. But if you look closely, and you go to the annexes, you see that it’s a real butcher’s shop. All of the suicidal volunteers left the study without it being written as is. They are classified in a category that means nothing, ’emotional lability’. This helps to hide the dangerousness of the drug.”
‘you see that it’s a real butcher’s shop’